LeonardoCA/Tools – par pomucek pro ladeni

- LeonardoCA
- Člen | 296
Postupne dopisu dokumentaci a testy, po delsi dobe si hraju s nette a prepsal jsem par pomucek aby fungovaly se soucasnou verzi a vzpominam co to vlastne umi
LeonardoCA/Tools
- obsahuje nekolik drobnych i vetsich pomucek k ladeni
Instalace a konfigurace
viz stranka rozsireni: https://componette.org/search/?…
- Shortcuts se pridavaji automaticky
- nektera funkcnost vyzaduje php extension tidy
SmartDump
- nahrazuje standartni Debugger::BarDump a pridava par vychytavek (BarDump funguje soucasne)
- vystup se posila do defaultniho nette panelu
- automaticky vytvari title s nazvem tridy a metody (nemusim si pamatovat kde jsem si dump dal)
- zobrazuje samotny vyraz pouzity v dumpu (nemusim si pamatovat co vlastne jsem vypisoval)
- v zavislosti na nastaveni v config.ini muze zobrazovat trace info (to se nekdy hodi, napriklad kdyz ladim jak se aplikace chova v zavislosti odkud se neco vola)
SmartDump::dump(<expresion>);
// zkratka
sdump(<expresion>);
// priklad:
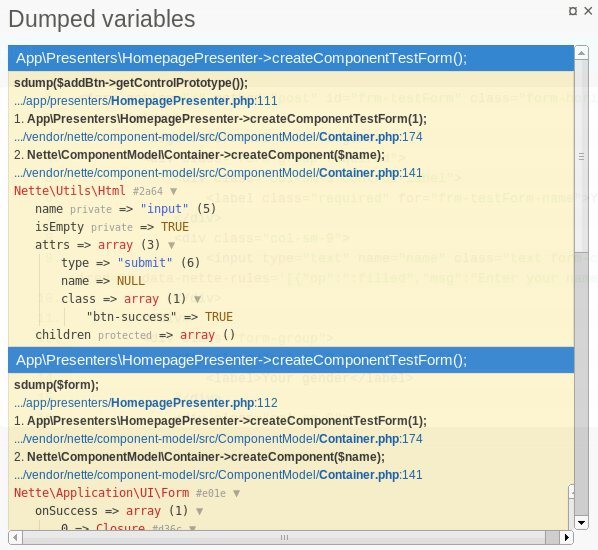
sdump($addBtn->getControlPrototype());
sdump($form);
vystup:
Vlozeni libovolne formatovaneho bloku do Dump Panelu
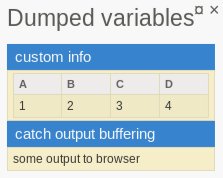
SmartDump::addToDumpPanel(
'
<table>
<tr><th>A</th><th>B</th><th>C</th><th>D</th></tr>
<tr><td>1</td><td>2</td><td>3</td><td>4</td></tr>
</table>
',
'custom info'
);
Output buffering ⇒ do standartniho bardump panelu
Obcas jsou situace, kdy se neda neco primo dumpovat a zapis s ob_start() atd mi prisel prilis dlouhy a proto vznikly zkratky. Konkretni situaci ve ktere jsem to potreboval si uz nevybavuju, ale jako priklad treba:
bs();
echo "some output to browser";
be('catch output buffering');
Ukazka vystupu:
Funkce s pripravenou konfiguraci tidy pro citelnejsi vystupy html a xml
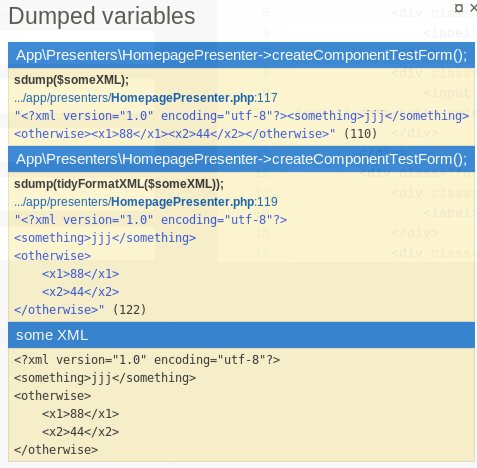
tidyFormatString($someHtml);
tidyFromatXML($someXML);
pro srovnani
$someXML =
'<?xml version="1.0" encoding="utf-8"?><something>jjj</something>
<otherwise><x1>88</x1><x2>44</x2></otherwise>';
sdump($someXML);
sdump(tidyFormatXML($someXML));
SmartDump::addToDumpPanel(
'<pre>' . htmlspecialchars(tidyFormatXML($someXML)) . '</pre>',
"some XML"
);
dumpHtml – pomucka pro ladeni Nette\Utils\Html
- vyrenderuje html element nebo block a zaroven zaroven zobrazi vygenerovany kod prohnany pres tidy a se zvyraznenim syntaxe
- da se vyuzit i behem ladeni sablon controls, apod
$someHtmlObject =
Nette\Utils\Html::el('a')->addClass('btn btn-danger')->setTitle(
'Danger'
)->setHtml('danger');
dumpHtml($someHtmlObject);

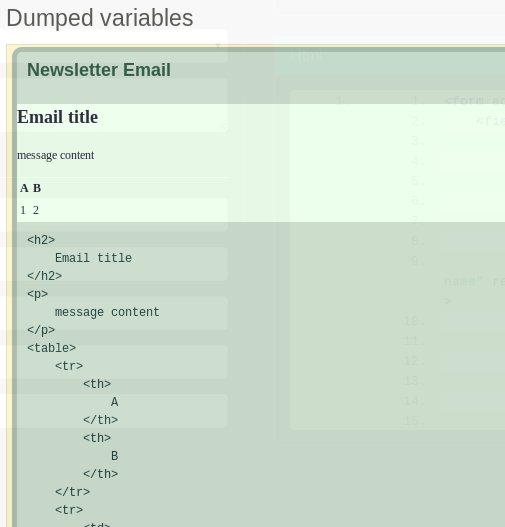
DumpMailer – zatim v hodne experimentalni podobe
services:
nette.mailer: LeonardoCA\Tools\DumpMailer
- zobrazi soucasne vyrenderovany email i jeho markup
- proc vytvaret novy panel, kdyz to muze jit opet do standartniho dump panelu
- zrovna jsem se v te dobe dozvedel o shadow DOM tak ne zcela doladeny pokus o jeho vyuziti
Editoval LeonardoCA (24. 9. 2014 22:04)
- LeonardoCA
- Člen | 296
ProcessMonitor
je pomucka pro ladeni dlouho bezicich scriptu nebo scriptu zpracovavajici velke mnozstvi dat – typicky importy/exporty, apod
- zkratky pro prehledne dumpy s ruznou urovni detailu informaci
- kazdy dump vystup obsahuje informaci o case a pouzite pameti
- moznost logovani klicovych casu
Priklad pouziti
(zde jen podstatna cast, cely funkcni fake priklad na https://github.com/…sMonitor.php)
// processMonitor extends Tracy\Debugger and mostly respects it's configuration
// therefore configure Debugger first
Debugger::detectDebugMode();
Debugger::enable();
Debugger::$maxDepth = 1;
// initialize ProcessMonitor
ProcessMonitor::$reportMode = ProcessMonitor::SHOW_DETAIL;
// ProcessMonitor::start is intended to be run only once
ProcessMonitor::start('some API import (this is only fake demo)');
$count = 0;
// this is how typical processing loop looks like
foreach ($filesList as $fileInfo) {
// while debugging scripts which repeat some actions multiple times
// reset process monitor timers in each loop
pmr('some api call to import ' . $fileInfo['name']);
// 1. step some api call
runApiCallToGetXMLFile($fileInfo, $memoryLeakData);
// pms is shortcut for ProcessMonitor::addSummary()
// when processing can be split in several steps as in this case
// it is very useful to track time and memory usage for each step separately
// track api call time + download response time
pms(
"get file {$fileInfo['name']} xml: " . ProcessMonitor::formatSize(
$fileInfo['size'] * 1000,
ProcessMonitor::SIZE_AUTO
)
. " <a href='/examples/processMonitor.php?file={$fileInfo['name']}'>Run again >> </a>"
. " <br/> see imported xml: <a href='/some_url/{$fileInfo['name']}' target='_blank'>"
. $fileInfo['name'] . "</a>",
null,
'time_api_call'
);
// 2. step - parsing xml response
parseXMLFile($fileInfo, $memoryLeakData);
// track time to validate and parse xml
pms('parsed ' . $fileInfo['name'], $fileInfo, 'time_parse');
// 3. step - preparing and storing data to db, etc
storeData($fileInfo, $memoryLeakData);
// track time to process and store the data
pms('processed ' . $fileInfo['name'], $fileInfo, 'time_processed');
// intentionally condition for always true in this example
if ($error = true) {
// pme is shortcut to output error messages
// you may include whatever data useful for debugging
// for more variables to dump use array
pme("Error description", ['some useful data']);
}
$count++;
}
pmr("XML files processed: $count");
pmr(
'Total run time: ' . ProcessMonitor::formatTime(
ProcessMonitor::getTotalTime()
)
);
vystup
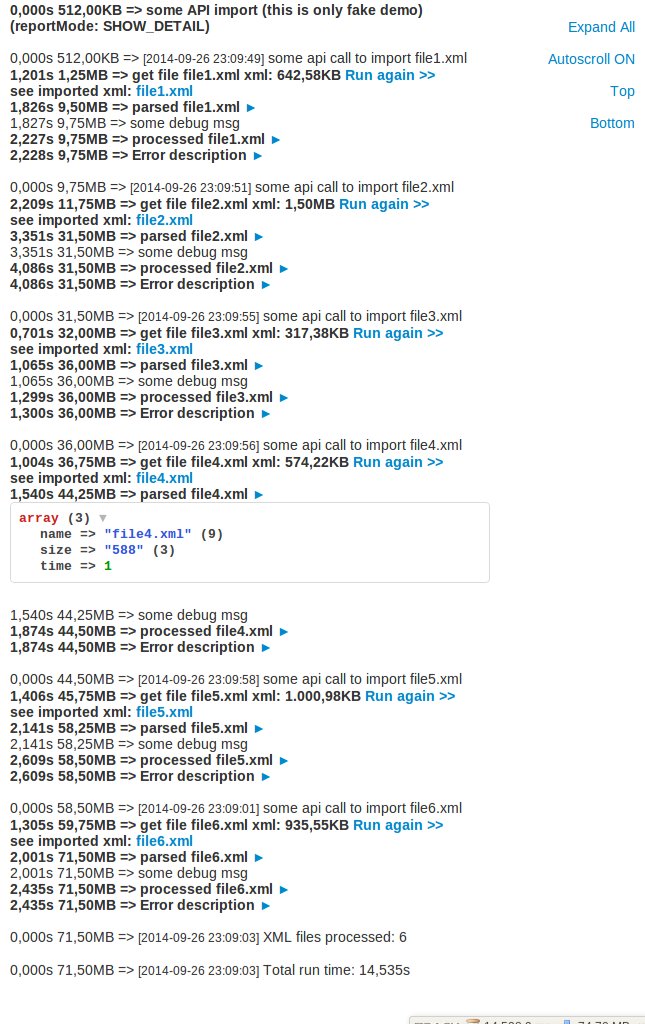
Nasimuloval jsem pripad, kdy je na prvni pohled videt ve skriptu, ktery zpracovava nekolik xml souboru, kde je nejvetsi problem: parsing zere velke mnozstvi pameti a hlavne ji vubec neuvolnuje…
ProcessMonitor umi zobrazovat velikost souboru/zabrane pameti automaticky v logicky nejblizsich jednotkach B, KB, MB, ale umoznuje si natvrdo vynutit nejake jednotky. Napriklad spotrebu pameti ma obvykle smysl zobrazovat v MB, ale pokud ladim memory leaks → jestli se nejaka pamet neztraci treba jen nevhodnym pouzitim promennych, hodi se nekdy i vypis v bytech, aby byl videt kazdy zbytecne pouzity byte …
Jak je videt v prikladu, za kazdym vypisem muze/nemusi byt sipka pro rozbaleni dumpu libovolnych dat pomoci Tracy\Dumper. Dumpy se (ne)generuji v zavislosti na nastaveni ProcessMonitor::$reportMode – tj vyhoda je, ze dumpy nemusim v kodu komentovat nebo je z kodu vyjimat a jsou pripravene pro opakovane pouziti kdykoli v budoucnu, kdyz se objevi nejaka chyba.
Editoval LeonardoCA (27. 9. 2014 0:38)
- LeonardoCA
- Člen | 296
Pridal jsem (o komentar vyse) malou ukazku jak se da vyuzit ProcessMonitor, ktery je jen drobnou nadstavbou nad Debugger. Napsat ilustracni priklad s fake importem mi zabralo vic casu nez jsem cekal, takze krom komentaru mezi radky jsem se k psani dokumentace nedostal. Kdyby to nekoho zajimalo vice, dejte vedet.
Editoval LeonardoCA (27. 9. 2014 0:12)
- LeonardoCA
- Člen | 296
Dokazu si predstavit, ze ani z prikladu neni uplne jasne k cemu vsemu je vlastne ProcessMonitor dobry, ze jsem se jeho zaklad snazil od zacatku pojmout jako samostatny znovupouzitelny script. Zkusim to trochu vic priblizit. Krome snadneho sledovani je-li potreba optimalizace kodu na rychlost nebo spotrebu pameti, je to totiz take vyborna pomucka k ladeni.
(Behem psani prikladu mi doslo, ze kod ProcessMonitoru sam o sobe je jen kostrou. ktera nedela skoro nic, az s tim jak se pouzije jde pak delat kouzla)
Priklad z praxe
Web ktery zobrazuje prakticky v realnem case veskere informace o vybranych fotbalovych ligach i online informace o probihajicich zapasech.
To co jsem v prikladu nasimuloval tremi dvouradkovymi funkcemi v praxi odpovida cca 30 tridam zajistujicim volani api, parsing, validaci a sanitizaci dat a zachyceni vsech chyb na vsech urovnich. Zadna chyba nesmi zpusobit pad nebo preruseni behu scriptu. Data se ukladaji do cca 70 databazovych tabulek.
pocatecni import do ciste databaze – neco pres 100.000 api requestu
denni import – radove tisice requestu
co 15min import – radove desitky requestu
co 15s import – 1 request
Prvotni vyvoj
Na zacatku scriptu, jeste pred smyckou pro zpracovani vice requestu, zavolam
inicializaci ProcessMonitor::start();
Nadefinuju si kroky importu, ktere ma pro mne smysl sledovat a v hlavni
smycce importu pro ne definuju vystupy pms() – ty se zobrazuji
ve vypise tucnym pismem a zobrazuji se v rezimu
ProcessMonitor::SHOW_NORMAL, navic tato zkratka funguje jako stopky
pro mereni casu kazdeho kroku zvlast – proto zkratku pms()
pouzivam jen v hlavni smycce a pro kazdy krok jen jednou az po jeho uplnem
dokonceni.
Behem prvotniho ladeni si pridam uvnitr trid resicich jednotlive kroky
vystupy pm() – ktere se zobrazuji jen v rezimu
ProcessMonitor::SHOW_DETAIL. Dam si tam vsechny informace, ktere
hojne behem ladeni potrebuji videt, napr – jak vypadaji data pred sanitizaci
a po, jak vypadaji sql queries pro update jednotlivych tabulek, atp
V mistech kde zpracovavam a loguju chyby si pridam vystupy pomoci zkratky
pme() (odlisne formatovani pro chyby)
Na konci smycky pridam nejakou hlasku pomoci zkratky pmr(), aby
se mi resetly vsechny sledovane casy a meril jsem casy pro kazdy request
samostatne.
Snadne ladeni obcasnych chyb v importech (nejen behem vyvoje)
Mam doladeno import jednoho typu requestu na jednom nebo nekolika xml? Zkusim pustit import vsech dat daneho typu, ale nejdriv se prepnu do rezimu ProcessMonitor::SHOW_NORMAL, protoze vypisovani detailnich informaci je jednak neprehledne a jednak zbytecne prodluzuje cas importu.
A ejhle, vsechno slape, az na request cislo 348, 485 a 567, ktere mi vyhazuji chybu. Jak to? Diky tomu ze jsem si vsechno behem prvotniho vyvoje pripravil, neni nic jednodussiho, nez:
- kliknout ve vypise na odkaz „Run again“ u requestu s chybou (v demu nefunguje, neni pro to implementovany router)
- prepnout se do rezimu
ProcessMonitor::SHOW_DETAIL(v realne aplikaci pro to mam taky odkaz v UI) - zobrazit si originalni data, kliknutim na odkaz v see imported xml (opet musi byt nejak realizovano pro konkretni pripad)
Vidim vse co potrebuji a i pokud dojde k nejake chybe po te co jsem na import nekolik mesicu nesahl a uz vubec netusim jak funguje, neni az takovy problem zjistit co se deje …
Vychytavky (uz zavisle na konkretni implementaci)
V realne aplikaci je cele test rozhrani integrovano do admin rozhrani webu, realizovano pomoci jedne komponenty a jednoho presenteru, ktery vystup renderuje do iframe uvnitr komponenty, veskere ladici informace a moznost testovat libovolny request jsou dostupne (diky menu a par prepinacu) bez jedineho zasahu do kodu…
Vystup do prohlizece je prubezny – typicky zpracovani
jednoho requestu trva radove sekundy, ale cele sequence casto minuty, ty
nejvetsi hodiny a proto na strane php zajistuje prubezny vystup do prohlizece
funkce flush(); a aby vystup nebrzdil buffering na strane
prohlizece, tak je i v prikladu pouzita finta, s odeslanim ukonceneho html
kodu prazdne stranky (</html>) a posilanim ladicich vystupu az pote. To je
podstatne k tomu aby fungovalo v prohlizeci prubezne vypisovani dat
i automaticke scrolovani na posledni vypis, ktere je
v prikladu take implementovano.
Editoval LeonardoCA (29. 9. 2014 11:45)