Nekorektní funkčnost ref()

- Eda
- Backer | 220
Mějme následující schéma databáze:
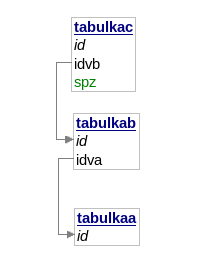
A tento kód například v presenteru:
foreach($db->table('tabulkac') as $c)
{
// varianta 1
//echo $c->ref('tabulkab','idvb')->id;
// varianta 2
//echo $c->ref('tabulkab')->id;
// varianta 3
//echo $c->tabulkab->id;
// varianta 4
//echo $c->ref('idvb')->id;
}
Když odkomentuju jeden z řádků, očekávám výpis „111222333“.
- Varianta 1 projde v pořádku a vrátí očekávaný výpis.
- Varianta 2 a varianta 3 NEprojde a skončí chybou
No reference found for $tabulkac->tabulkab., byť tento cizí klíč existuje. - Varianta 4 projde v pořádku a vrátí očekávaný výpis navzdory tomu, že je to blbost. V argumentu funkce ref() totiž dle všechn dostupných zdrojů má být uvedena tabulka, ze které chci navázaný záznam, nikoliv sloupec rodičovské tabulky, přes který je záznam navázán.
Dump databáze, na které jsem to testoval, je zde
K testování jsem použil vývojovou verzi budoucího Nette 2.0.4, dále Nette 2.1-dev, následně i hrachovy větve f-db-dev i f-database-refactoring. U všech to fungovalo stejně.
Problémem je pravděpodobně implementace funkce
getBelongsToReference(). Má to také další nepříjemný efekt.
Když chceme filtrovat záznamy podle kritérií z cizích tabulek, které jsou
navázány přes více tabulek, nyní musíme psát něco jako:
$db->table('tabulkaV')->where('tabulkaX:tabulkaY:sloupectabulkyy.sloupectabulkyz', $value);
Což je velmi matoucí a než jsem přišel na to, že to tak funguje, tak jsem málem zešedivěl :-) V ideálním případě by to mělo vypadat takto:
$db->table('tabulkaV')->where('tabulkaX:tabulkaY:tabulkaZ.sloupectabulkyz', $value);
Co navrhuji:
- opravit chybu v kódu
- přejmenovat první parametr funkce ref() na
$tablenebo$childTable, aby bylo na první pohled jasné, co v tomto parametru má být. Stávající$keyje nicneříkající. - na druhou stranu bychom ale mohli zvážit, jestli neposkytnout přístup k navázanému záznamu přes vazební sloupec v nějaké regulérní funkci záměrně. Např. columnRef()? Nevím. Někdy se to ale může hodit. (Já jsem si několik dní myslel, že uvedené chování je správné, a tak můj ORM je postaven tak, že s tímto počítá… Tak proč to nezachovat, aby to Eda zase nemusel celé přepisovat :-) )
- tento hrachův slajd dát do dokumentace. Hned bude vše jasnější při pátrání po chybách a pochopení fungování N\DB.
- v dokumentaci vysvětlit, kde má být název sloupce, kde jméno tabulky a jak funguje tečková/dvojtečková notace. Když děláte s vazbami přes více tabulek, je nutné v tom mít jasno a příklad s klihou a autorem pomalu přestává stačit…
(Kdybych náhodou nereagoval na odpovědi, mějte pochopení, budu pravděpodobně nějaký ten pátek offline… :-( )
Editoval Eda (27. 7. 2012 2:59)

- hrach
- Člen | 1845
Zatim zareaguji jen na prvni cast:
- ocekavane chovani je spravne, akorat spatne pochopene.
- je treba jasne rozlisovat, kdy je metoda ref volana s dvema argumenty a kdy jen s jednim.
- bohuzel, v mluvenem slovu sem dany slide spatne vysvetlil. Tedy jeden dany radek.
Takze:
$book->ref('author')->name;
$book->author->name;
$book->translator->name;
mají stejnou logiku, prvni dva jsou navic ekvivalentni. Znamena to: „V tabulce book hledej sloupec, ktery obsahuje v nazvu ‚author‘ nebo ‚translator‘ a nacti patricnou tabulku, kam z nich vede foreign klic.“ Tedy translator najde sloupec translator_id a nacte tabulku, kam ukazuje foreign klic.
Zbyle dva zapisy
$book->ref('author', 'author_id')->name;
$book->ref('author', 'translator_id')->name;
Naopak uz jasne definuji, co se ma delat: „Najdi tabulku author a spoj se s ni pres sloupec ‚author_id‘.“
Z vyse uvedeneho pak vypliva, ze chovani danych 4. bodu je spravne.
Edit: no, ted sem to trochu zase zamotal. To, co sem rikal v prednasce plati, ale jen pro discovered reflection. Vyse napsany popis je obecnejsi a v podstate dulezitejsi pro DiscoveredReflection.
Editoval hrach (27. 7. 2012 9:22)
- hrach
- Člen | 1845
K druhe casti, jestli to dobre chapu, melo by tam byt:
$db->table('tabulkaV')->where('tabulkaX:tabulkaY:tabulkaZ:sloupectabulkyz', $value);
Chapu ze ta dvojtecka je neintuitivni, chastam zmenu, aby to fungovalo takhle:
$db->table('tabulkaV')->where(':tabulkaX:tabulkaY:tabulkaZ.sloupectabulkyz', $value);
- Eda
- Backer | 220
Aha. Tak to jsem tedy netušil. Nebo tušil, ale nevěděl.
- připadá mi to ale brutálně magické a neintuitivní. Možná je to tím,
že nejsem zvyklý používat zde běžné konvence (na běžícím projektu
bohužel člověk nemůže ze dne na den změnit schéma DB…). Navíc jsem
zvyklý nové tabulky pojmenovávat právě přímo jako název entity:
uzivatel,vuz,dopravcea podobně. Pak dává smysl $vuz->dopravce->nazev, což teď bohužel nejde a musím psát buď $vuz->iddopravce->nazev nebo $vuz->ref(‚dopravce‘, ‚iddopravce‘). Jedno horší jak druhé… Co kdyby šlo nějak nastavit výchozí chování v této věci? To by bylo ideál. Výchozí by mohlo být, jak je to teď a Eda-style by bylo optional :-) - když nepoužívám konvenci „table_id“ pro cizí klíč, není možné dostat se k hodnotám v potomkovi přes atribut, protože $tabulkaC->idvb je hodnota přímo klíče
- je to strašná magie. Takto to funguje samo a člověk, který o tom neví, tak se to prostě nedozví jinak, než tak, že se mu to rozdrbe a pak hodiny hledá a hledá…
- osobně mi přijde, že tohle je fakt velká změna v chování, která je závislá jen na počtu parametrů. A to není moc Nette-way :-) Kdyby to aspoň bylo někde nějak souhrnně vysvětleno… Až to API bude stabilní, klidně nějaký článeček do dokumentace napíšu, to není problém…
- proč nenabídnout API, kde budu přistupovat k vazbám jen pomocí tabulek? To by mi přišlo intuitivní…
Ad druhá část:
- naopak, dvojtečka mi přijde jako úplně geniální výmysl :-)
- nene. Mám to správně v příspěvku. Jde mi o schéma databáze: tabulkaV ← tabulkaX ← tabulkaY → tabulkaZ. A přes tyhle všechny tabulky chci vyhledávat, jednou vazba 1:N mezi V a X, pak vazba M:N mezi X a Z přes tabulku Y…
- jde mi jen o to, že kvůli popisovanému chování funkce
getBelongsToReferencejsem v tom „hledacím řetězci“ musel na „třetím místě“ použít název vazebního sloupce místo navázané tabulky (v pozadí se volá tato funkce stejně, jako kdybych volal $table(‚tabulkaX‘)->ref(‚sloupecVxPresKteryJenavazanoY‘)). Což je matoucí a doufám, že tohle není cílové očekávané chování…
Editoval Eda (27. 7. 2012 10:30)
- hrach
- Člen | 1845
ref:
- ocividne si to moc nepochopil ;)
- pouzivame jen DiscoveredReflection, to jedine ma smysl.
- aktualni stav je opravdu chytry, vyzaduje jen urcitou logiku:
$vuz->dopravce->nazevfunguje, pokud tabulka vuz ma jakykoliv sloupec, ktery obsahuje slovo dopravce. tzn.dopravce_id,iddopravce,dopravceId, atp.- to volani ->dopravce nemuze byt cilova tabulka, pac pak by $user->translator->name bylo naprosto nepouzitelne.
- metoda ref s jednim parametrem by se v podstate nemela vubec volat, jeji publikovani je vcelku nevhodne. :)
- to, ze mas zpraseny navrh db, kdy sloupec
idbvvede natabulkavfakt zadny orm nezachrani. ;)
- Eda
- Backer | 220
- Kritiku schémata databáze přijímám. Kdybych to teď psal odznova, udělám to úplně jinak. Jenomže před pěti lety jsem o nějakých konvencích bohužel neměl ani potuchy…
- A jak se řeší situace, kdy mám z tabulky
vuzcizí klíče do tabulkydopravce,vuzdopravce,vuzdopravcenazevdopravce,vuzdopravcespzatd. To pak pro přístup do tabulky dopravce musím použít prostě ref… Jasný, pomalu se začínám chytat :-) - Fakt je to docela chytré :-) Tohle vlákno a ty tvé vysvětlující body by to chtělo přetavit do dokumentace, aby to každý další hned pochopil, né jak já :-)
- ad příklad:
schéma:
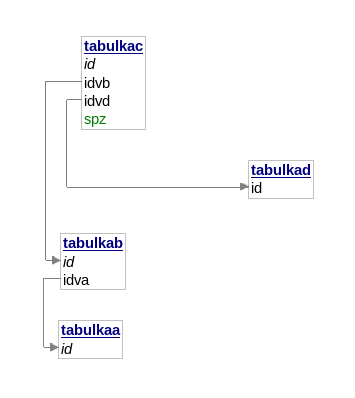
Chci vybrat z A zaznamy s vazbou do D s D.id = 1: Jak na to?
foreach($db->table('tabulkaa')->where('tabulkab:tabulkac:idvd.id', '1') as $a)
{
echo $a->id;
}
Tohle mi ještě v nějakých předchozích verzích fungovalo. A tohle jsem právě kritizoval. Jestli to fungovalo náhodou, všechno je v pořádku :-)
Nicméně:
foreach($db->table('tabulkaa')->where('tabulkab:tabulkac:tabulkad.id', '1') as $a)
{
echo $a->id;
}
//...No reference found for $tabulkac->tabulkad.
foreach($db->table('tabulkaa')->where('tabulkab:tabulkac:tabulkad:id', '1') as $a)
{
echo $a->id;
}
//...No reference found for $tabulkac->related(tabulkad).
Ani jeden z těchto cyklů nefunguje (větev f-database-refactoring)… A protože mi to nefungovalo i předtím, tak jsem začal vymýšlet kraviny a ono to (asi náhodou) fungovalo :-)
SQLdump: zde
Dodatek: Stejné chyby jako nahoře vrací i jednodušší hledání:
foreach($db->table('tabulkac')->where('tabulkad:id', '1') as $a)
{
echo $a->id;
}
foreach($db->table('tabulkac')->where('tabulkad.id', '1') as $a)
{
echo $a->id;
}
Dotaz: Tečka vs. dvojtečka se projeví tím, jestli je z pohledu cizího
klíče první tabulka rodičovská nebo potomkem. Projeví se to i na
výsledném SQL dotazu, nebo ne?
Kacířská myšlenka: Co takhle z pohledu API používat jen tečku a navenek
nerozlišovat, odkud kam ten klíč vede? Asi bude někde nějaký háček, že?
Napadá mne možná jen řezení, kde bychom mohli chtít použít LEFT místo
INNERu…
Pomalu se mi všechno začíná vyjasňovat, díky za konstruktivní diskusi :-)
Editoval Eda (27. 7. 2012 11:55)
- hrach
- Člen | 1845
A jak se řeší situace, kdy mám z tabulky vuz cizí klíče do tabulky dopravce, vuzdopravce, vuzdopravcenazevdopravce, vuzdopravcespz atd. To pak pro přístup do tabulky dopravce musím použít prostě ref… Jasný, pomalu se začínám chytat :-)
- pokud vazby na dane tabulky jsou pres sloupce dupravce_id, vuzdropravce_id, vudopravcenazevdoprave_id, atp… tak samozrejme to jde bez ref :)
- mas moznost si podedit reflection a trochu si to ohnout ;)
- hrach
- Člen | 1845
schéma:
Uz sem na to prisel. Ono je to spravne, ze ti to nefunguje. Je to ten stejny trik jako s ref. Proste ve chvili, kdy pouzivas DiscoveredRefelction to nepojit pres nazev tabulky, ale klic, ze ktereho se odvodi nazev sloupce. To ti pak dovoluje napsat
$connection->table('book')->select('id, moderator.name')->fetchPairs('id', 'name');
Takze je to cajk :)
Jak napsat dvou-parametrove volani fet v ramci sql: to jeste nejde, mam to
v planu udelat :)
- jsvelta
- Člen | 39

- připadá mi to ale brutálně magické a neintuitivní. Možná je to tím, že nejsem zvyklý používat zde běžné konvence (na běžícím projektu bohužel člověk nemůže ze dne na den změnit schéma DB…). Navíc jsem zvyklý nové tabulky pojmenovávat právě přímo jako název entity:
uzivatel,vuz,dopravcea podobně. Pak dává smysl $vuz->dopravce->nazev, což teď bohužel nejde a musím psát buď $vuz->iddopravce->nazev nebo $vuz->ref(‚dopravce‘, ‚iddopravce‘).
Odkazovať sa štýlom
$vuz->dopravce->nazev
je dosť krátkozraké. Vezmime si, že máme tabuľku bankových účtov
nazvanú account. Ďalej tabuľku platobných príkazov
payment_order so stľpcami account_debit_id a
account_credit_id. Oba stľpce odkazujú pochopitelne do tabuľky
account. Čo by malo vrátiť následujúce volenie?
$payment_order->account->number
Logickejšie je práve nasledujúce volanie:
$payment_order->account_credit->number
- bumprask
- Člen | 59

@hrach:
Měl bych jednu výtku k funkčnosti také ohledně referencí, ovšem
tentokrát ohledně referencí na úrovni třídy Table\Selection, tedy při
sestavování dotazu v metodě
table(‚nazev_tabulky‘)->select(‚…‘).
Struktura tabulky, na kterou chci joinovat všechny tabulky na které má přímou referenci, tedy hlavně tyto:
TELEFON
...
firemni_tarif_id (cizí klíč do tabulky TARIF)
osobni_tarif_id (cizí klíč do tabulky TARIF)
...
Potřebuji jednoduše sestavit dotaz, který vypíše konkrétně ke každému číslu názvy obou tarifů dle reference. Nemůžu nad výsledkem iterovat, tudíž potřebuji najoinovaný výsledek už na úrovni Table\Selection, o což se pokouším následovně:
//můj prvni pokus, který skončí chybou vygenerováním špatného SQL, kvůli nemožnosti dodržení jmenných konvencí u dvou atributů odkazujících do stejné tabulky.
$model->table('telefon')
->select('firemni_tarif.nazev AS firemni_tarif,
osobni_tarif.nazev AS osobni_tarif')
//jelikož je tedy třeba určit referenci ručně, použil jsem verzi Database, u které je možná následující syntaxe pro manuální join
$model->table('telefon')
->select('(tarif,firemni_tarif_id).nazev AS firemni_tarif,
(tarif,osobni_tarif_id).nazev AS osobni_tarif')
//zde jsem již očekával funkčnost, ovšem Database se v tomto případě nechová dle očekávání
//vygenerovany SQL dotaz
SELECT tarif.nazev AS firemni_tarif,
tarif.nazev AS osobni_tarif
FROM telefon
LEFT JOIN tarif ON telefon.osobni_tarif_id = tarif.id
Problém je, že výsledný SQL zahrnuje pouze jeden JOIN tabulky tarif bez aliasu a to na poslední definovaný dotaz o spojeni tabulek. Kdyby Database uvážil možnost více klíčů do jedné tabulky s čímž souvisí nemožnost dodržení konvencí, vytvořil by dva LEFT JOIN pro každý tarif a se svým aliasem. Vypadá to, že Table\Selection s touto variantou dvou klíču do jedné tabulky nepočítá,což je asi jediná situace, kdy s ním nelze získat požadovaná data (u mě zásadní!)
Nebo tomu tak není? Jde takovýto select uskutečnit? Dělám to špatně?
Prosím o radu, děkuji moc.
Editoval bumprask (8. 3. 2013 15:44)

- enumag
- Člen | 2118
@bumprask: Takový dotaz pomocí Selection nyní není možné napsat. V zásadě bys to ale stejně dělat neměl, jak jsem ti už vysvětloval. Opět porušuješ ten samý princip. ;-)
Že NDB aktuálně neumožňuje přijoinovat jednu tabulku dvakrát pro výběr dat nevnímám jako zásadní problém. Horší je, že tu tabulku nemohu přijoinovat dvakrát ani kvůli where podmínkám, což už může být vážnější a dle mého názoru by se to mělo vyřešit. Řešení by nejspíše zprovoznilo i ten select.
- bumprask
- Člen | 59
No jo no, ono je sice možné jako nouzovku použít ->query() na jakýkoliv složitější dotaz, ovšem tato metoda vrací pouze statické pole a s ní ztrácím možnost jakéhokoliv dalšího FILTROVÁNÍ dotazu pozdějšíma podmínkama a vůbec celou onu pohodlnost při práci s Table\Selection, která je potřeba myslím hlavně v každém gridu založeném na Database.
- Radek V
- Člen | 1

Dobrý den
Potřeboval bych ve vazbě m:n definovat filtry nad oběma tabulkami. Nad tou
první je to snadné, ale chtěl bych přidat podmínku do té druhé. Ve výše
uvedeném příkladu by to bylo filtrování dle SPZ v tabulce C
Žádná z kombinací teček a dvojteček mi nefunguje.
foreach($db->table('tabulkaa')->where('tabulkab:tabulkac:spz', '1P3 1234') as $a)
V principu potřebuji doplnit poslední vygenerovaný dotaz o nějaký and:
SELECT * FROM tabulkac WHERE
(tabulkac.id IN (21, 22, 23)) …and
tabulka.spz=‚1P3 1234‘
Procházení a porovnávání parametrů není zcela efektivní.
Můžete mi prosím poradit? Předpokládám, že nejsem první, kdo to
řeší. Díky